Business In The Loop™
AI/GenAI Platform












-
 PEPSICO
PEPSICOIT Manager – Commercial Products Lead
TAZI’s remarkable ability to consider factors such as seasons, prices, marketing activities, and gift offers has resulted in a 98% prediction accuracy for 86% of hundreds of products in our portfolio.
-
 IS INVESTMENT
IS INVESTMENTRiza Kutlusoy – CEO
We have completed the 3rd year of our collaboration with TAZI. The synergy created by our corporate expertise combined with TAZI’s specialization has increased the effectiveness and efficiency of our customer retention efforts. Thanks to TAZI’s approach referred to as ‘Business in the loop,’ our teams can easily engage in processes. One of the strengths of TAZI is the ease of working with TAZI teams and the robustness of their support system.
-
 PEMCO
PEMCOBusiness Intelligence Analyst
TAZI makes every step of the machine learning process easier. Without TAZI it would have likely been years before we could have deployed our own machine learning models into production.













-
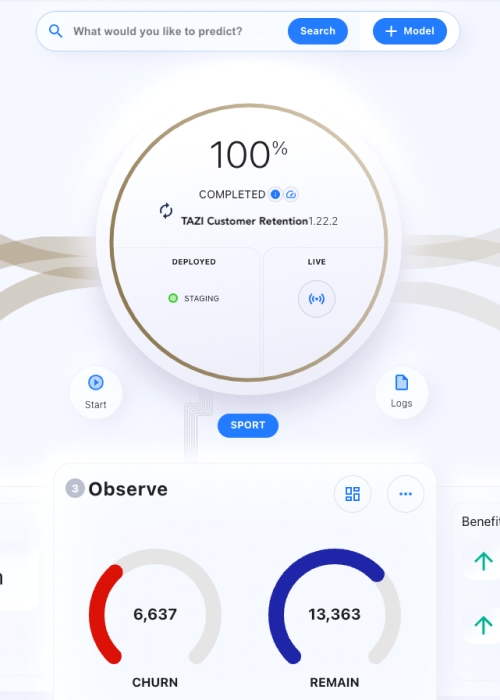
 Easy to UseTAZI can be used by business users who don’t have data science training, such as business analyst or a C-level executive.
Easy to UseTAZI can be used by business users who don’t have data science training, such as business analyst or a C-level executive. -
 Time to valueTAZI provides explanations to business users on data, models and results, business users can take actions or update data or models based on what they see.
Time to valueTAZI provides explanations to business users on data, models and results, business users can take actions or update data or models based on what they see. -
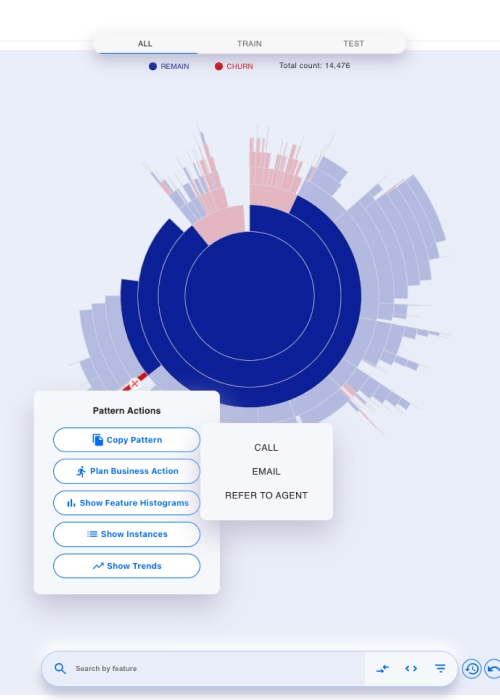
 AdaptiveTAZI models can learn in while they are in production, they adapt to changes in data and reducing errors, IT&data science MLOps efforts and cloud computing costs.
AdaptiveTAZI models can learn in while they are in production, they adapt to changes in data and reducing errors, IT&data science MLOps efforts and cloud computing costs. -
 Business-FocusedTAZI is highly focused on business outcome and ROI of AI predictions.
Business-FocusedTAZI is highly focused on business outcome and ROI of AI predictions.